Sebastian Pieczynski's website and blog
Published on: yyyy.mm.dd
Published on: yyyy.mm.dd
Created with ❤️ by Sebastian Pieczyński © 2023-2026.
Published on: 11/23/2023

How arrrr... ya Engineers? 🦜
Seems to me we have found ourselves a mighty trrr...easure.. after our last trip. We just need to dig it up...
Stop dilly dallying and let's get to work. Today we are digging data from the web pages and claiming it as our own.
This is a two part article. In the first we will build full scraper from start to finish and in the second we'll take care of the backend and frontend.
Note to people who do this daily - please send your suggestions how to improve the crawler. It is my first attempt at such a project and it is not as efficient as it could be (no concurrency) but was a fun to make and if possible I would also love to learn more from You.
For those that want to follow along here's the link to a stepped solution . The main branch has finished code and other branches are separated by steps as per this article.
The original repo at: GitHub requires some changes but present a working and finished project. It is not a curated repository so you will be able to see the thought process and what went right and what needed changing in the course of building it.. and what bugs 🐛 crept in.
REST API will be very limited as it's not a proper implementation of a backend server.
The initial scraper implementation was inspired by: https://www.zenrows.com/blog/javascript-web-crawler-nodejs#create-web-crawler-in-node
After longer than usual intro let's get started.
We found a treasure trove 🏝️ of data but the problem is it's on the website without a way to export it. To dig that treasure we'll need some tools:
In part 1 we'll go through points 1-4 and in part 2 we'll finish our application.
We have to get data for all the products listed on a certain website. And for that we need to dig our way through the DOM to get the information about the product:
For the source of data we'll be using the Pokemon Shop ScrapeMe shop site that has all the products listed on ~50 pages.
To get the data we'll use the Axios and to query the DOM of the fetched pages we'll use the CheerioJS libraries.
Since we want to use both Typescript and ESM modules we'll use tsx package to run our scraper server.
To start clone the init branch from the stepped repo .
This will clone the repository to web-scraper-stepped-solution folder. If you already have a folder created you can add a . (dot) at the end to clone into current directory.
After the repository is cloned install the dependencies:
Then in the root of the project (next to src directory) create a scraper.ts file in the root of the project and import both axios and cheerio and create a main function that will run the scraper:
Then in the package.json file inside "scripts" section add the following:
Running the script should return
If you have issues at this stage you can open an issue on GitHub or contact me directly.
The maxPages parameter will be important to control the number of pages to crawl.
For index of visited pages we'll use a Set. This structure is simillar to an array but it does not allow duplicates so it will be perfect to keep track of what page was visited. Even if we try to add the same page a second time Set will not add the same value again. Read more about Sets on MDN here .
Inside main function we'll first look for all the pages that we can crawl and add the links to the queue. Then we'll visit each page (download with Axios) and check for the existence of data we need in the HTML content. Let's dive into the code and I'll guide you with the comments alongside it.
Well first check navigation for all pages and add them to the crawl list:

The image shows that it is possible to access the link for a page with .page-numbers a selector.
Now for the actual product data we can use the li.product a.woocommerce-LoopProduct-link selector:
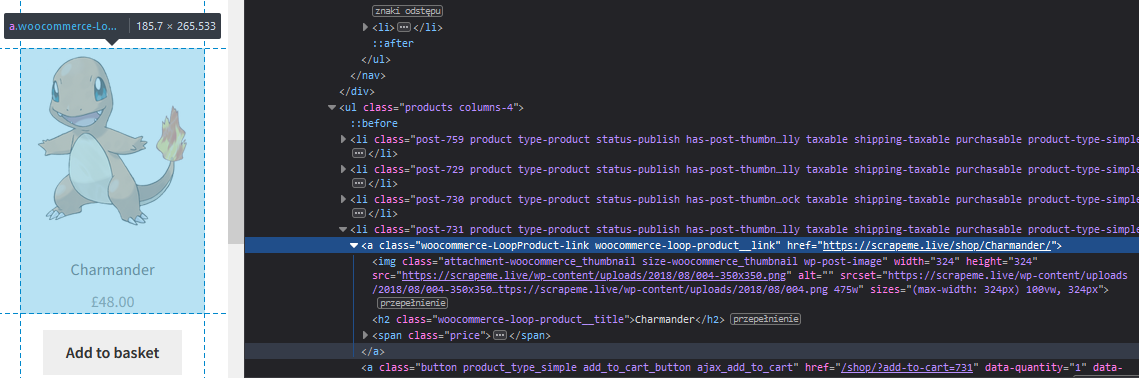
The keen eyed will also note that there is a lot more data there that we are interested in. We'll get it all later for now let's get minimal version up and running.
With that in mind let's modify the main function inside the scraper.ts:
Running this code should return an array of product URLs, but since it's just logged to the console we cannot do much with them.
The repository has a branch with code at this stage here .
The "magic" happens between the lines where we first get the content of the webpage and then send it to cheerio for parsing.
After that we can query it with jQuery like syntax:
For now our scraper doesn't do much but there is everything in place for us to get all that shiny data if we so desire.
For reference here's the full source of the initial scraper:
If you have any issues along the way here is the finished code for this section: prisma and seeding script .
Now we will add database connectivity to our scraper, this will allow us to process the data later without accessing the site again.
First we need to add prisma to our project as a dependency:
and then initialize the database connection:
This will create a new prisma folder with schema.prisma file inside and .env file in the root of the directory.
We'll modify these files in a moment.
Before continuing make sure that in .gitignore any .env files are set to ignored in the commits, BUT not .env.dist.
You can exclude a file pattern in .gitignore by adding an ! before the pattern or file name.
Add the following at the end of the .gitignore file:
Create additional file: .env.dist. We will use .env file as our source of truth in production and .env.dist as a sample or reference file.
When you clone the full repository .env file will not be present so .env.dist will tell you what environmental variables you need to set to successfully run the project.
In the .env set DATABASE_URL to the following:
You can set .env.dist file to have the same contents as .env but remember to keep all secrets out of .env.dist file.
With this configuration present Prisma (when run) will create a /data/dev.db file and subfolder inside /prisma folder.
Now we need to design our database schema. We'll keep it simple but fairly robust for the use case. We'll assume the most important aspect for our users is the price of the product but we'll keep all additional information in the database as JSON.
Prisma does not support JSON field type for sqlite so we'll use a string and parse it when necessary.
We'll also have the User model to test our database connection.
Modify the prisma/prisma.schema file:
Points to note about the schema:
id field is auto-generated and unique and uses CUID as value of an id field.createdAt and updatedAt fields are auto-generated.url so it will be a unique field.data will hold any data we extract and do not need to directly operate on (ex. filter).dataType is there to distinguish between different types of data we could obtain and will not be used in our examples, it's there to give you an idea how to expand the scraper capabilities ex. templates.Let's get ready to test our database connection.
And this is a real gem in this article:
It is possible to SEED prisma database with seed script written in typescript and using ESM imports!
Try it in a project without tsx installed. I have, it's not fun..
Add a prisma seed script to the package.json file. It's a "standalone" configuration that does not belong in "scripts" section.:
Before writing the seed script generate the prisma client:
This will create all the methods that we will need inside seed and scraper to work with prisma.
After that we need to synchronize model with the database. For now we can push the model as database does not exist yet and we do not care about migrations.
This will create all folders required and a database file.
We are finally ready to create the seed.ts file inside prisma folder:
Run the seeding script with:
npx will run the prisma script from node_modules and execute the seed.ts with tsx. It should return in the console:
Our database connection works and the seed script can be run multiple times thanks to using upsert, you can try again.
Update the .gitignore file to keep our database from being sent to the repository:
A side note to Next.js developers reading this: this method also works with Next.js! Tested and confirmed. You're welcome!
If you have any issues along the way here is the finished code for this section: saving product data to the database .
Now that we have our database connected and confirmed it works let's add the same capability to the scraper. We'll also extract more information about the product and save it to the database.
As you can see not much was really needed in the scraper code itself to make it work.
We have added a function that saves the product data to the database and extracted information about the product from the website. The function for prisma works the same way as the seeding function, but if you do have questions please contact me.
If you run the scraper now you should see the products in the database. You can use HeidiSQL to view the data in the database.
Added data should also be displayed in the console:
Now there are last twp things we need to take care of. If you check inside the database you'll see that the images are linked from the original site.

This is not good on many levels: we might be overusing the bandwidth or external site and these images may be removed at some point. Let's try limiting our impact on the site and download the images to our folder and serve them on our own.
The second issue is that at some point you can see an error that more than 10 PrismaClients have been created.
If you have any issues along the way here is the finished code for this section: saving product data to the database .
To remedy that we'll create a single instance of the PrismaClient. Create a src/lib/prisma.ts file.
From now on we can reference the prisma variable from the lib/prisma.ts instead of creating new the client every time. This will be important in part 2.
To download data we will use node and axios. First let's create a function that will receive a list of files to download, note that we are using prisma from our lib folder here:
We have imported the fs and path to make working with local files possible and imported prisma from the lib folder.:
Then we declare the function that will accept an Array of strings that will represent links to files we need to download:
As we loop through all the files with for loop we'll extract information from the link to get the name of the file. With it we can can set a custom save location for it.
We also save the full url to the original file as a local variable.
Before downloading files we need to make sure that folder is created:
Then we loop over all the files in the list and wait for the stream to be saved to disk with createFile function we declared earlier.
createFile function wraps a stream in a Promise so that it can resolve after file is written to disk and closed or rejects if something goes wrong. Without it we would not have saved all the files. File is created inside the ./public/images folder.
We keep a count of how many files have been downloaded and present that information to the user. That way we know if all the files were downloaded.
Finally in the main function we're adding a Set where we'll keep links to images we want to download called imageSrc:
If you have NOT copied the code above please remember to remove the creation of the new PrismaClient:
After having files available locally let's modify the data of the product before saving it in the database as so that image url will point to a local image not to one from the original website:
And finally just before the end of the main function download the images:
You can also add images folder to .gitignore file to keep source code clean:
If you inspect the data in HeidiSQL now you will see that we have relative images set for the products.

With this our scraper (shovel to unearth the treasures) is completed.
In this part of the series we have:
In the next part we'll create a frontend and a backend to serve the data and visually present it to the users.
See you soon!
Below is the full source of the finished scraper.ts.
It wasn't as hard as it seemed right?
Let me know what you think or send a PR with improvements!
See you next time!
Back to Articles